4주 차에서는 메트릭 오픈소스인 프로메테우스 오퍼레이터를 공부했습니다. 프로메테우스 오퍼레이터를 이용하여 메트릭 수집방법과 알림기능 실습했습니다.
이번 주차에는 github copilot도움을 받아 프로메테우스 오퍼레이터를 작성했습니다. 사용할 수록 인공지능 성능에 반하고 있습니다.😂
1. 메트릭 시스템 소개
프로메테우스를 공부하기 전에 메트릭 시스템이 무엇인지 아는 것이 좋다고 생각했습니다. 그래서 이 글은 메트릭 시스템 소개로 시작하여 프로메테우스를 설명합니다.
1.1 메트릭 시스템이란?
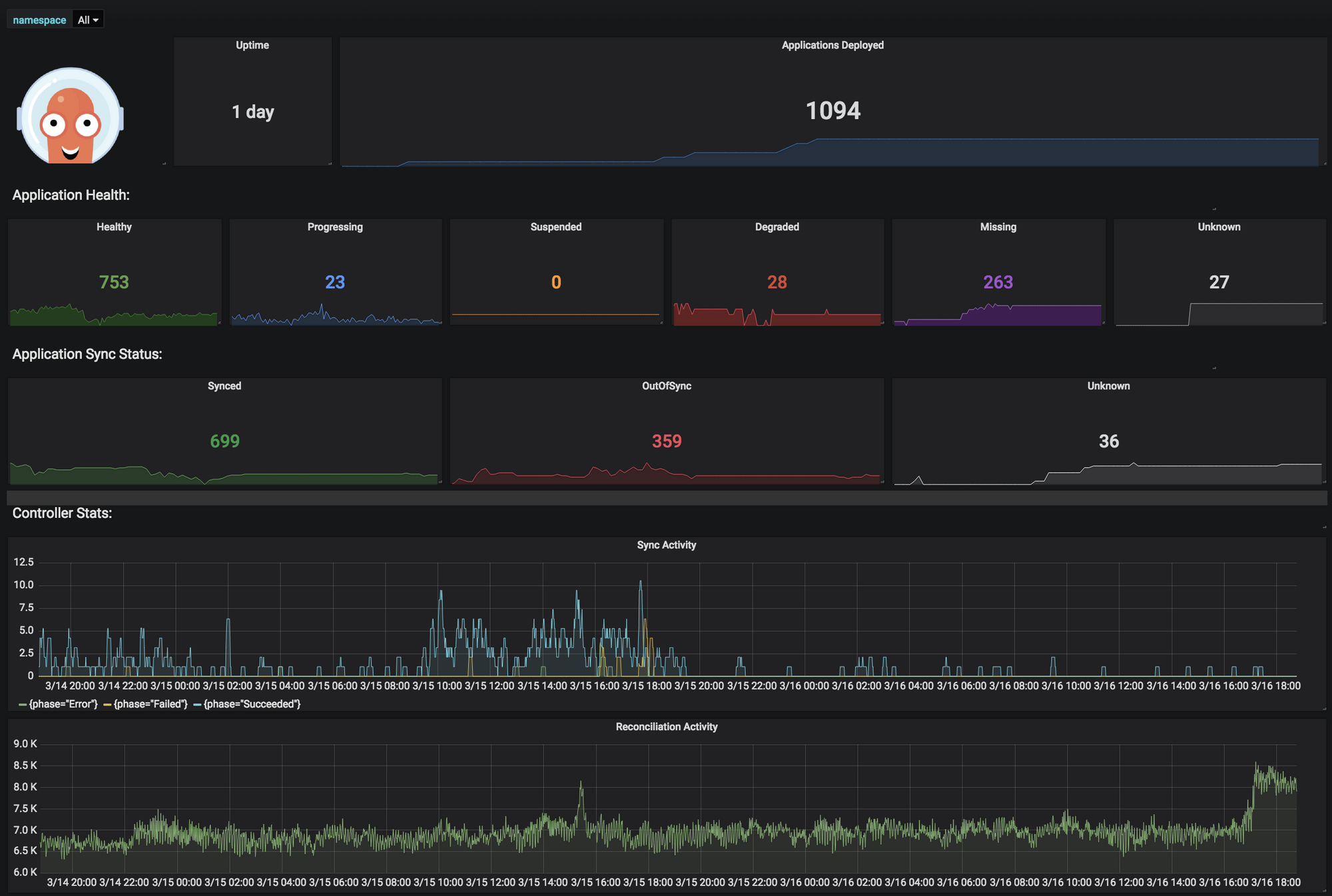
메트릭 시스템이란 목표대상의 상태값을 수집하고 관리하는 시스템입니다. 상태값은 자원사용률(cpu, memory 등) 또는 애플리케이션 수치(API호출 횟수 등)를 의미합니다.
아래 그림은 메트릭 시스템이 수집한 Argo cd 메트릭을 보여주는 예입니다.
1.2 왜 필요할까?
저는 메트릭 시스템을 도입했을 때 두 가지 장점을 얻을 수 있다고 생각합니다.
1️⃣ 장애를 빠르게 인식하고 장애처리 시간을 단축
시스템을 구축하면 알게모르게 사용자가 알아채지 못한 장애가 수시로 발생합니다. 그리고 많은 장애가 수시로 복구됩니다. 복구되지 않은 장애는 사용자가 직접 장애처리를 해야 합니다. 메트릭 시스템을 도입하면 장애가 발생할 때 알림을 발생시킬 수 있습니다.
2️⃣ 메트릭을 분석하여 성능 개선
시간대별로 자원 사용률, 특정 상태 값 등 현재 상태값을 분석하여 성능을 개선시킬 수 있습니다. 예를 들어 점심시간에 서비스 사용자가 폭주하여 cpu사용률이 거의 100%가 되었다면, 점심시간에만 CPU코어수를 증가시켜 성능을 개선할 수 있습니다.
1.3 메트릭 시스템 공통 기능
메트릭 시스템을 구현한 많은 솔루션들이 있습니다. 이 솔루션들의 공통 기능은 메트릭 수집, 저장, 조회, 알림입니다.
1️⃣ 측정항목설정: 어떤 항목을 측정할지 설정합니다.
2️⃣ 메트릭 수집: 측정항목을 설정한 대로 메트릭을 수집합니다.
3️⃣ 메트릭 저장: 수집한 메트릭을 저장합니다.
4️⃣ 메트릭 조회: 저장된 메트릭을 조회할 수 있습니다.
5️⃣ 가시성: 조회한 메트릭을 시각화할 수 있습니다.
6️⃣ 알림: 메트릭이 특정 수치에 부합하면 사용자에게 알림을 전달합니다.
1.4 메트릭 시스템을 도입 시 생각해야 할 것
메트릭 시스템을 도입하면 기술도 중요하지만, 정책을 정의하는 것이 더 중요하다고 생각합니다. 어떤 기준으로 메트릭을 수집할지, 어떤 메트릭 기준으로 알림을 사용자에게 보낼 것인 지 등이 정책에 해당합니다.
그리고 메트릭 시스템에 적용할 때는 저장장치 계산이 많이 필요합니다. 메트릭은 초단위로 수집하기 때문에 짧은 시간에 100GB 이상 메트릭이 저장될 수 있습니다. 저장용량은 한정되어 있기 때문에 오래된 메트릭은 삭제할 수밖에 없습니다. 그래서 메트릭 시스템을 현업에 적용할 때는 인프라 엔지니어 또는 스토리지 엔지니어 협업이 필요합니다.
- 정책
- 어떤 측정항목을 설정할 것인가?
- 메트릭은 며칠 동안 보관할 것인가?
- 장기 저장소를 사용할 것인가?
- 메트릭 조회를 위한 식별값은 어떻게 할 것인가?
- 알림 기준은 무엇인가?
- 기술
- 어떻게 수집할 것인가? (pull vs push)
- 시각화는 어떻게 할 것인가?
- 알림을 위해 추가 개발이 필요한가?
2. 프로메테우스와 프로메테우스 오퍼레이터
2.1 프로메테우스란?
프로메테우스는 메트릭 오픈소스입니다. 메트릭 시스템을 구축할 때 많이 사용합니다. 프로메테우스는 메트릭 수집과 저장, 알림 기능을 지원합니다. 그리고 그라파나와 연동하여 저장된 메트릭을 시각화 할 수 있습니다.
쿠버네티스에서 프로메테우스를 사용한다면, 프로메테우스 오퍼레이터를 사용하는 것이 관리가 편합니다. pkos 스터디에서는 프로메테우스 오퍼레이터를 활용하여 메트릭 시스템을 공부했습니다.
프로메테우스로 메트릭을 다루는 방법은 제 유투브에 소개되어 있습니다.
2.2 프로메테우스 오퍼레이터란?
프로메테우스 오퍼레이터(prometheus operator)는 프로메테우스를 쿠버네티스 오퍼레이터패턴으로 관리합니다. 프로메테우스 설치부터 설정관리까지 쿠버네티스 CRD로 관리합니다.
CRD로 프로메테우스를 관리하면 어떤 장점이 있을까요? 프로메테우스를 쿠버네티스럽게 다룰 수 있어, 쉽게 프로메테우스 관련 설정을 정의하고 배포할 수 있습니다.
예를 들어 프로메테우스를 설치하고 싶으면 kind: prometheus를 사용하면 됩니다. 프로메테우스 statefulset, service, ingress가 생성됩니다.
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
podMonitorSelector: {}
다른 예는 프로메테우스 타겟을 추가하고 싶으면 servicemonitor, podmonitor를 사용하면 됩니다. 아래 예제는 argocd를 타겟으로 추가하는 예제입니다.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: argocd-metrics
namespace: argocd
labels:
release: prometheus-argocd
spec:
selector:
matchLabels:
app.kubernetes.io/name: argocd-metrics
endpoints:
- port: metrics
3. 프로메테우스 스택 설치
3.1 설치방법
프로메테우스 스택은 프로메테우스 오퍼레이터와 그라파나를 설치합니다. 그리고 쿠버네티스 메트릭 관련 프로메테우스 설정을 합니다.
저는 helm 차트를 사용하여 스택을 설치했습니다. 먼저 helm 차트 주소를 추가합니다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm values 오버라이딩 값을 설정합니다. 저는 AWS ALB와 TLS설정을 했습니다.
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:467606240901:certificate/248292f9-a31b-46b7-be91-b1e23a2b9a70
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.${your_domain}
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: ${CERT_ARN}
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.${your_domain}
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: ${CERT_ARN}
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.${your_domain}
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
scrapeInterval: 15s
evaluationInterval: 15s
helm install명령어로 helm차트를 릴리즈합니다. 네임스페이스는 monitoring을 지정했습니다.
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 45.7.1 \
-f values.yaml \
--namespace monitoring --create-namespace
3.2 설치확인
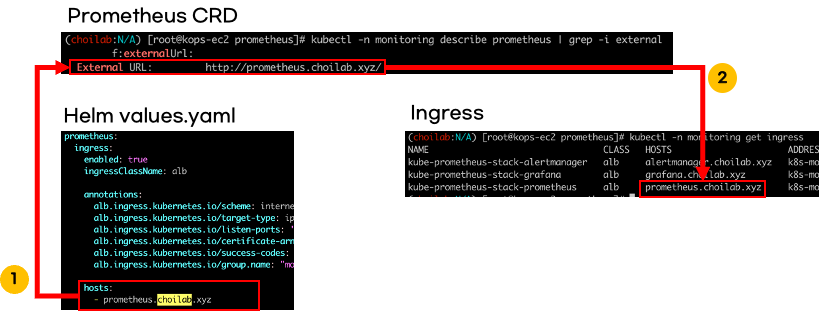
프로메테우스 스택을 설치하면 프로메테우스가 기본으로 설치되어 있습니다. 설치된 프로메테우스는 프로메테우스 CRD를 사용했습니다. 프로메테우스 접속 주소는 helm 오버라이딩 values에 설정한 값입니다.
프로메테우스 설정도 잘 되어 있습니다. 설정 또한 CRD를 사용합니다. 예를 들어 coredns 타겟설정은 servicemonitor로 되어 있고, 오퍼레이터에 의해 자동으로 프로메테우스에 설정됩니다.
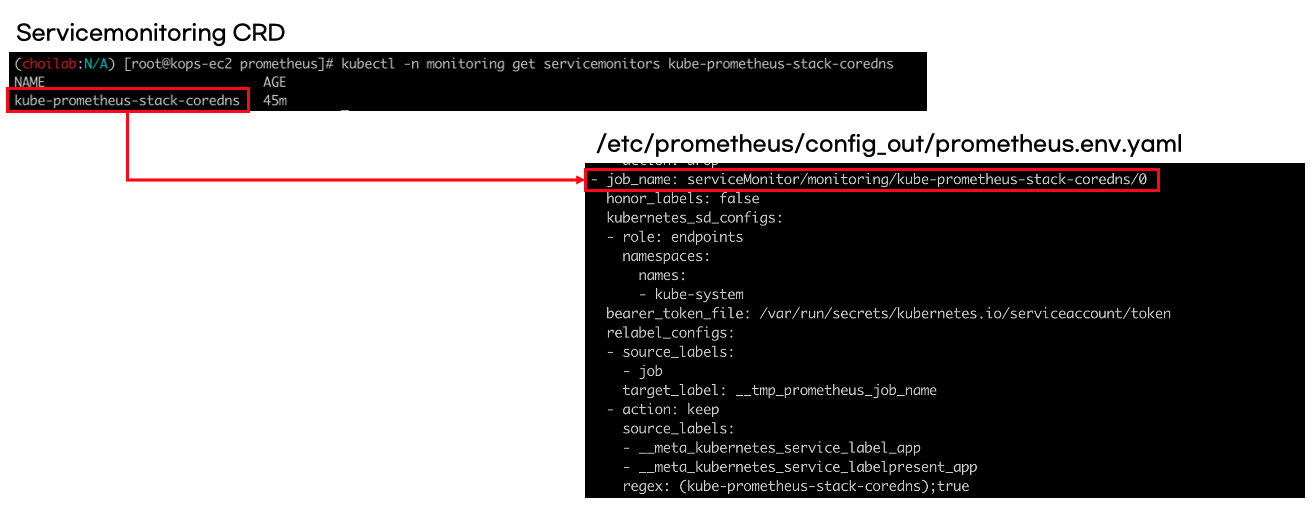
CRD 타겟설정은 프로메테우스 서버에서도 확인할 수 있습니다.
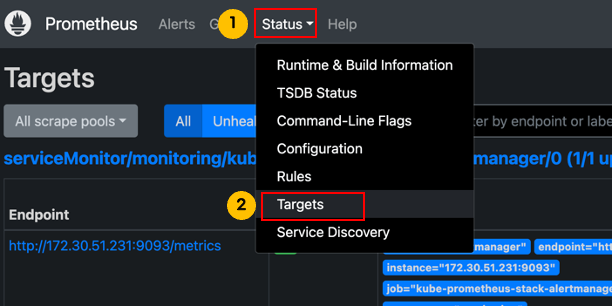
4. 프로메테우스와 프로메테우스 오퍼레이터 타겟추가
이 챕터는 프로메테우스에 타겟을 추가하는 방법과 프로메테우스 오퍼레이터에서 타겟을 추가하는 방법을 살펴봅니다. 프로메테우스 예제코드는 제 github에 공개되어 있습니다.
메트릭 예제 github 링크: https://github.com/sungwook-practice/python-prometheus-metrics
4.1 메트릭 예제 애플리케이션
예제 애플리케이션은 간단한 API입니다. API를 호출 횟수를 메트릭으로 노출시킵니다.
from fastapi import FastAPI
from prometheus_client import start_http_server, Counter
# 메트릭 포트
METRIC_PORT = 8090
app = FastAPI()
start_http_server(METRIC_PORT)
# 메트릭 정의
REQUEST_COUNTER = Counter('hello_world_requests', 'Number of requests to hello_world API')
# API 정의
@app.get("/")
async def root():
# Increment the counter for each request
REQUEST_COUNTER.inc()
return {"msg": "helloworld"}
정의한 메트릭은 http://1270.0.1:8090/metrics에서 보실 수 있습니다. 처음 메트릭을 조회하면 API호출횟수가 0이므로 메트릭 값 또한 0입니다.
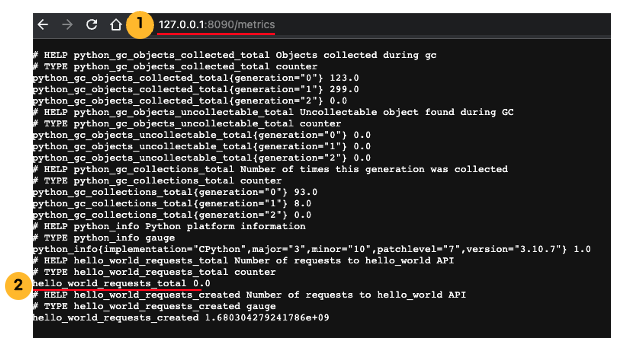
API(http://127.0.0.1:8000)를 호출하면 메트릭이 증가합니다. 아래 예제는 API를 13번 호출한 결과입니다.

4.2 프로메테우스 타겟 추가
이 실습을 진행하기 위해 프로메테우스가 로컬 PC에 설치되어 있어야 합니다.
프로메테우스 타겟에 파이썬 웹 애플리케이션을 추가해보겠습니다. scrape_config필드에 파이썬 웹 애플리케이션 메트릭 포트를 추가하면 됩니다.
# vi /opt/homebrew/etc/prometheus.yml(macOS 위치)
global:
scrape_interval: 15s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 파이썬 웹 애플리케이션 추가
- job_name: "python-tests"
static_configs:
- targets: ["localhost:8090"]
타겟 설정이 끝나고 프로메테우스를 재실행합니다.
# macOS전용
brew services restart prometheus
그리고 프로메테우스 서버에 들어가서 타겟설정을 확인합니다. 파이썬 애플리케이션이 목록에서 보여야하고 상태가 UP이어햐합니다.
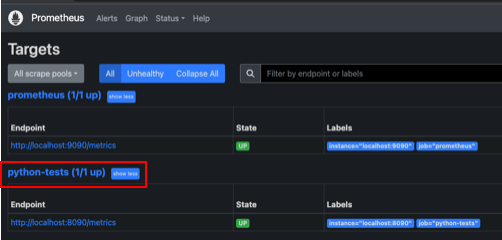
이제 프로메테우스 서버에서 메트릭을 조회할 수 있습니다. "hello_world_requests_total"로 검색하면 메트릭이 조회됩니다.
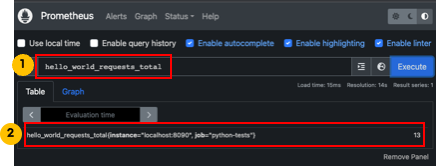
4.3 프로메테우스 오퍼레이터로 타겟 추가
[4.2]챕터에서 실습했던 타겟설정을 프로메테우스 오퍼레이터로 해보겠습니다.
먼저 파이썬 웹 애플리케이션을 쿠버네티스에 배포합니다. pod와 service를 정의했습니다. service는 실습을 편하게 하기 위해 nodeport를 사용했습니다.
# kubectl apply -f deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-client-demo
labels:
app: prometheus-client-demo
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-client-demo
template:
metadata:
labels:
app: prometheus-client-demo
spec:
containers:
- name: prometheus-client-demo
image: choisunguk/prometheus-python-deo:0.1
ports:
- containerPort: 80
- containerPort: 8090
resources:
requests:
cpu: 0.2
memory: 128Mi
limits:
cpu: 0.2
memory: 128Mi
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-client-demo
labels:
app: prometheus-client-demo
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30091
- name: metrics
port: 8090
targetPort: 8090
nodePort: 30092
selector:
app: prometheus-client-demo
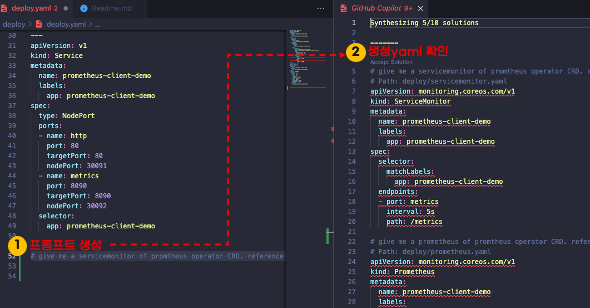
servicemonitor를 사용해서 타겟을 추가하겠습니다. 설정 방법은 매우 간단합니다. servicemonitor selector에서 service label를 지정하면 됩니다. 자세한 내용은 프로메테우스 오퍼레이터 공식문서를 참고하세요.
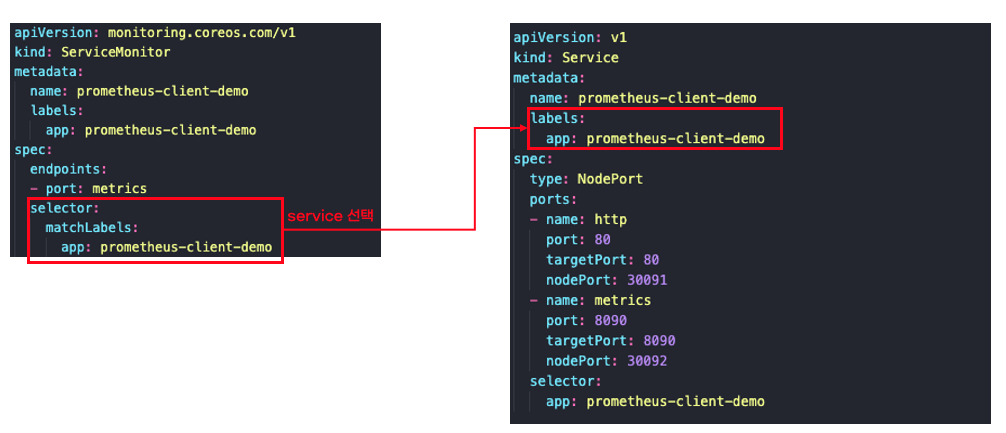
# kubectl apply -f servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: prometheus-client-demo
labels:
app: prometheus-client-demo
spec:
endpoints:
- port: metrics
selector:
matchLabels:
app: prometheus-client-demo
servicemonitor를 적용하면 프로메테우스 설정과 다르게 프로메테우스를 재실행하지 않아도 됩니다. 약 30초정도 기다리면 자동으로 설정이 적용됩니다. 프로메테우스 서버에서 타겟설정을 확인하면 아래 그림처럼 servicemonitor에 설정한 적용이 잘 반영되었습니다.

파이썬 웹 애플리케이션에서 정의한 "hello_world_requests_total"메트릭도 조회해보세요. 잘 조회됩니다!
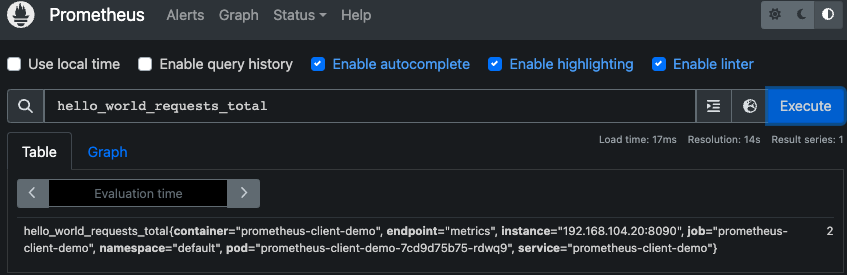
5. 프로메테우스 익스포터(Exporter)
[챕터 5]에서는 공개되어 있는 메트릭을 어떻게 불러오는지 설명합니다.
5.1 익스포터란?
익스포터는 메트릭을 미리 만들어 놓은 것을 말합니다. 익스포터를 사용하면 [챕터 4]파이썬 웹 애플리케이션 메트릭 예제처럼 메트릭을 만들필요 없습니다. 사용자는 메트릭 수집설정만 하면 됩니다.
자신이 만들지 않은 서비스의 메트릭을 만드는 것은 쉽지 않습니다. 서비스 기능을 이해해야하고 어떤 메트릭을 노출시켜야 효율적인지 고민해야할 부분이 많습니다. 익스포터는 이 고민과정을 많이 단축시켜줍니다.
프로메테우스 점유율이 높아지면서, 해당 애플리케이션 또는 시스템 이해도가 높은 사람 또는 개발자가 직접 익스포터를 만들어 공개도 계속 증가하고 있습니다. 감사하게도 프로메테우스 오퍼레이터전용 익스포터 공개 사례도 증가하고 있습니다.
5.2 예제: nginx ingress
nginx ingress에서 공식 익스포터를 제공합니다. helm차트를 사용하여 쉽게 익스포터를 설정할 수 있어요. helm values를 아래처럼 오버라이딩 servicemonitor가 생성됩니다.
controller:
metrics:
enabled: true
serviceMonitor:
enabled: true
helm install명령어로 helm 차트를 릴리즈 합니다. 저는 infra라는 namespace에 생성했습니다.
# nginx ingress helm 차트 추가
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
# helm 차트 릴리즈
helm install -n infra --create-namespace -f values.yaml nginx ingress-nginx/ingress-nginx
servicemonitor가 잘 생성되었는지 확인합니다.
kubectl -n infra get servicemonitor
프로메테우스 서버에 접속하여 nginx ingress servicemonitor가 타겟에 추가되었는지 확인합니다.
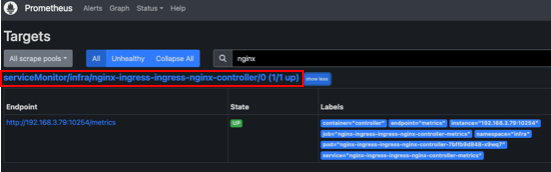
nginx ingress 익스포터가 제공하는 메트릭은 공식문서를 참고하시면 됩니다. 메트릭을 이해하고 활용하는것은 많은 사용경험이 필요하므로, 메트릭사용 목적을 정의하고 메트릭을 관찰하는 것을 추천드립니다.

6. 프로메테우스 알림
6.1 알림이란
프로메테우스 알림은 메트릭 특정기준이 되면 사용자에게 알림을 보내는 기능입니다. 프로메테우스가 알림조건을 검사하고 alertmanager에게 조건에 충족된 알림을 전파(Fire)합니다. alertmanager는 받은 알림을 사용자게에 전달합니다.
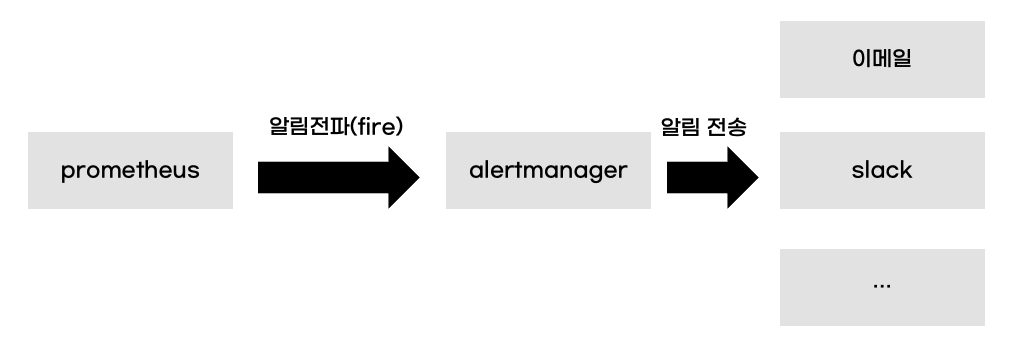
6.2 프로메테우스 알림 예제
[챕터 4]에서 만든 파이썬 API 호출횟수가 15개가 넘으면 알림을 발생시키는 예제를 실습합니다.
- 알림등록
알림설정은 yml로 설정합니다. 그리고 프로메테우스 설정파일에서 알림설정파일을 로드하도록 설정해야 합니다. 아래 예제는 rules폴더에 있는 example.yml파일을 알림설정으로 읽도록 설정했습니다.
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "python-tests"
static_configs:
- targets: ["localhost:8090"]
# 알림폴더 지정
rule_files:
- "rules/example.yml"
rules/example.yml파일에 예제 알림을 설정했습니다.
# rules/example.yml
groups:
- name: hello-request-over
rules:
- alert: Conguration-over.
expr: hello_world_requests_total{job="python-tests"} > 15
labels:
severity: info
위 알림설정을 보면 expr에 알림 조건을 설정 했는데, 자세히 보시면 메트릭을 이용한 계산식입니다. 계산식은 프로메테우스 서버에서 검증을 한 후 알림에 설정할 수 있습니다.
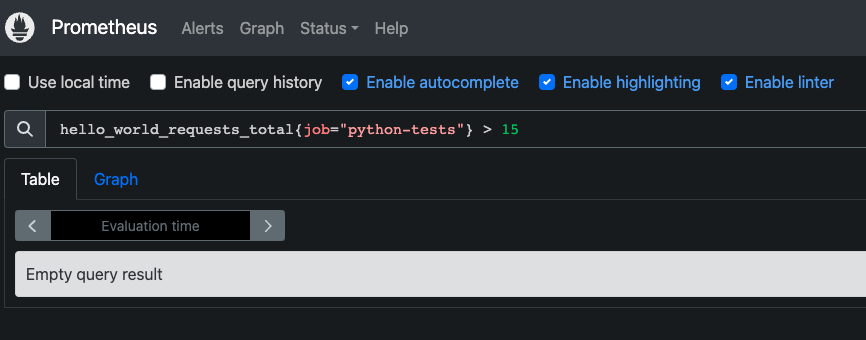
프로메테우스를 재실행하고 프로메테우스 알림이 잘 등록되었는지 확인합니다.
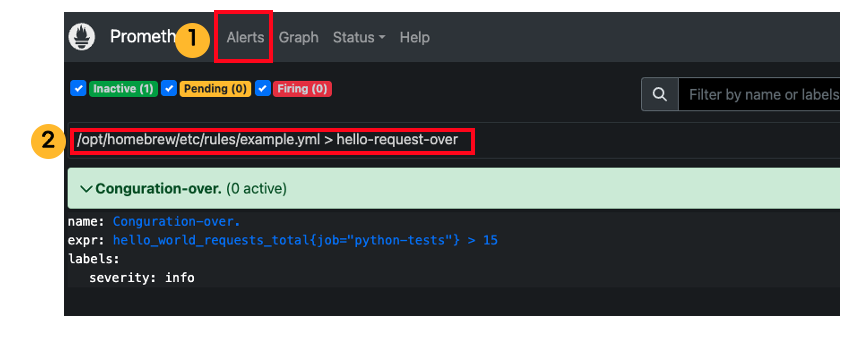
- 알림 조건 발생시키기
알림 조건으로 등록한 hello_world_reqeusts_total은 파이썬 API가 호출해야 증가합니다. 현재 10개이므로 아직 알림상태가 inactivate상태입니다.
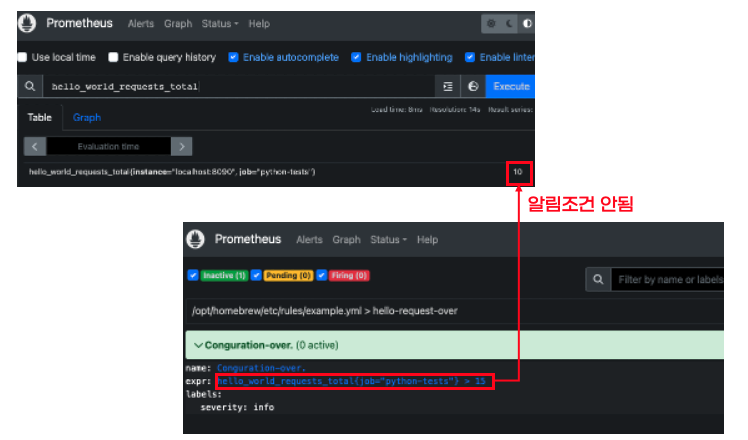
수동으로 파이썬 API를 15번이상 호출해보고 알림을 다시 확인해볼게요. 파이썬 API는 http://127.0.0.1:8000으로 호출할 수 있습니다. API 15번 호출 후 약 30초 기다리면 알림이 발생(Fire)했습니다.
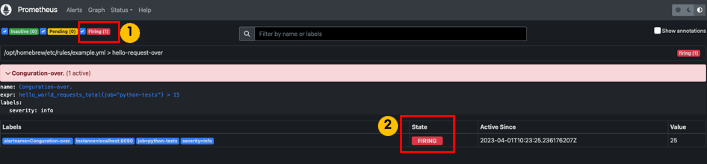
발생한 알림은 "ALERTS" 메트릭으로도 조회할 수 있습니다.
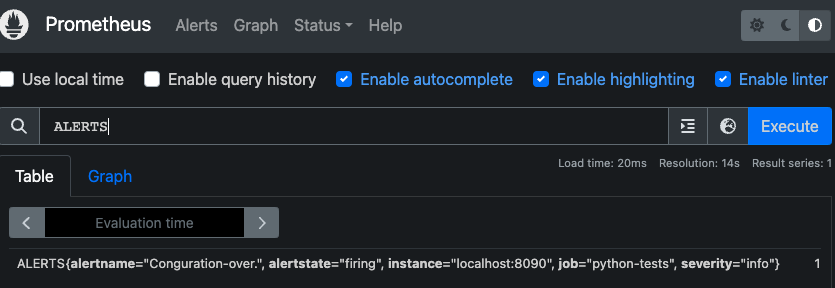
6.3 alertmanager 예제
[챕터 6.2]에서 에서 발생한 알림을 alertmanager를 이용하여 slack으로 전송하는 예제를 실습합니다. 예제를 실습하기 위해 slack 워크스페이스, 채널, 앱이 필요합니다.
- slack 워크스페이스 생성
알림 테스트를 위해 slack 워크스페이스를 생성합니다. slack 워크스페이스 생성은 공식문서에 자세히 설명되어 있습니다. 문서에서 설명한 과정을 따라하면 slack 워크스페이스가 생성됩니다. 저는 "alarm-test"라는 이름으로 워크스페이스를 만들었습니다.
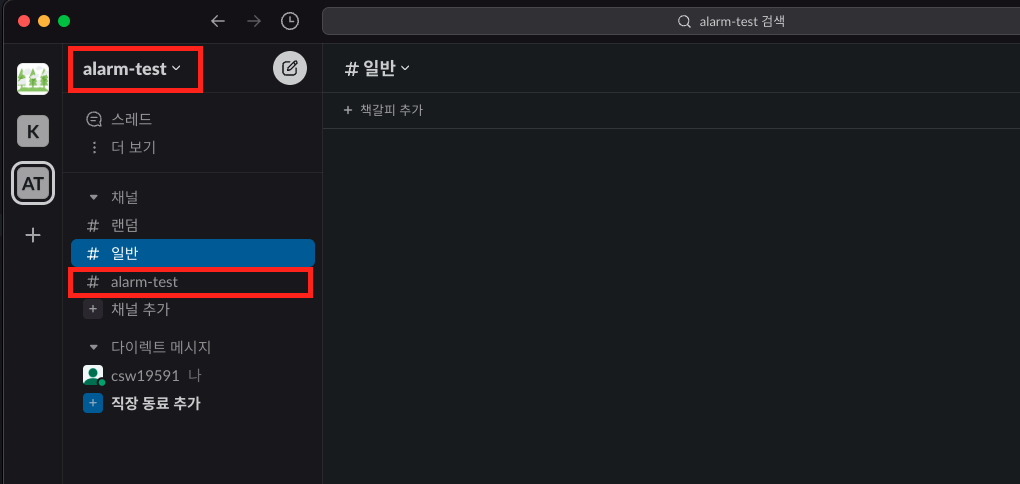
- slack 채널 생성
알림을 전송할 slack채널을 생성합니다. 저는 이전 과정에서 생성한 워크스페이스 안에 alarm-test라는 채널을 만들었습니다.
- slack 앱 생성
slack 앱 생성페이지에 접속 한 후 앱 생성버튼을 클릭합니다.
저는 이전 과정에서 생성한 워크스페이스를 사용했습니다.

- slack 웹훅 생성
slack 앱이 프로메테우가 전달한 알림을 받기 위해 웹훅을 생성합니다.
먼저 웹훅을 활성화 합니다. 그리고 웹훅 생성버튼을 클릭하여 웹훅을 생성합니다.
웹훅을 만들 때 slack 채널을 지정해야 합니다. 저는 이전과정에서 만든 slack채널을 설정했습니다.

웹훅이 생성되면 웹훅주소가 생성됩니다.
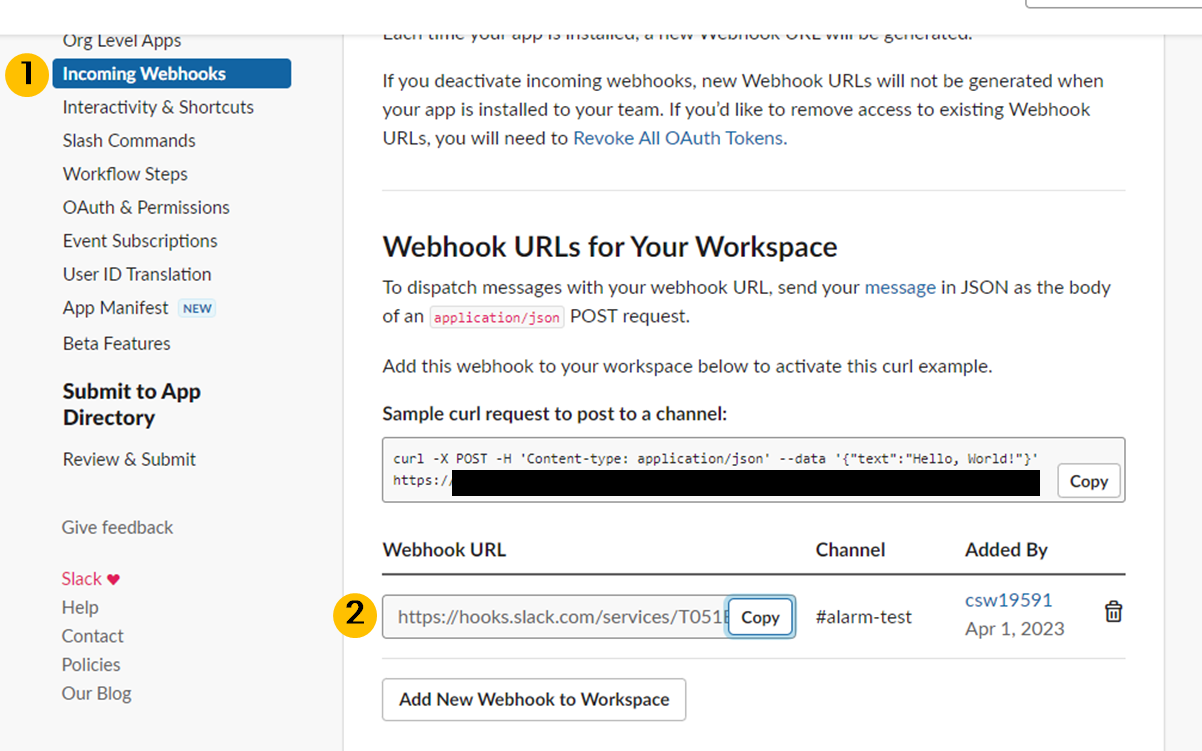
- alertmanager 다운로드
alertmanager는 github release에서 다운받을 수 있습니다. 설치 필요없이 다운로드 받은 압축파일을 압축해제만 하면 됩니다.
- alertmanager 설정
압축해제한 경로로 이동해서 alertmanager 설정을 수정합니다. slack 알림설정은 alertmanager공식문서를 참조하면 좋습니다. slack에 보낼 메세지는 recivers.name.channel.text에 설정할 수 있습니다. 저는 간단하게 축하메세지 문자열만 설정했습니다.
global:
slack_api_url: 'Slack WEB HOOK URL'
route:
receiver: 'hello-request'
group_by: ['test']
group_wait: 30s
group_interval: 1m
repeat_interval: 3h
receivers:
- name: 'hello-request'
slack_configs:
- channel: '#alarm-test'
text: "Conguration. your request is over 15"
- alertmanager 실행
alertmanager설정이 끝났으니, alertmanager압축해제한 경로로 이동한 후 alertmanager를 실행합니다. 정상 실행되면 리스닝 포트가 출력됩니다.

- 프로메테우스와 alertmanager 연결
이제 마지막 단계입니다. 프로메테우스와 alertmanager를 연결하면 됩니다. 연결설정은 prometheus.yml에서 합니다.
global:
scrape_interval: 15s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "python-tests"
static_configs:
- targets: ["localhost:8090"]
# alertmanager 연결 설정
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- "rules/example.yml"
- alertmanager와 slacker알림 확인
프로메테우스를 재실행 하고 약 15초(프로메테우스 설정)정도 기다리면, 프로테메우스가 alertmanager에게 알림을 전송합니다.
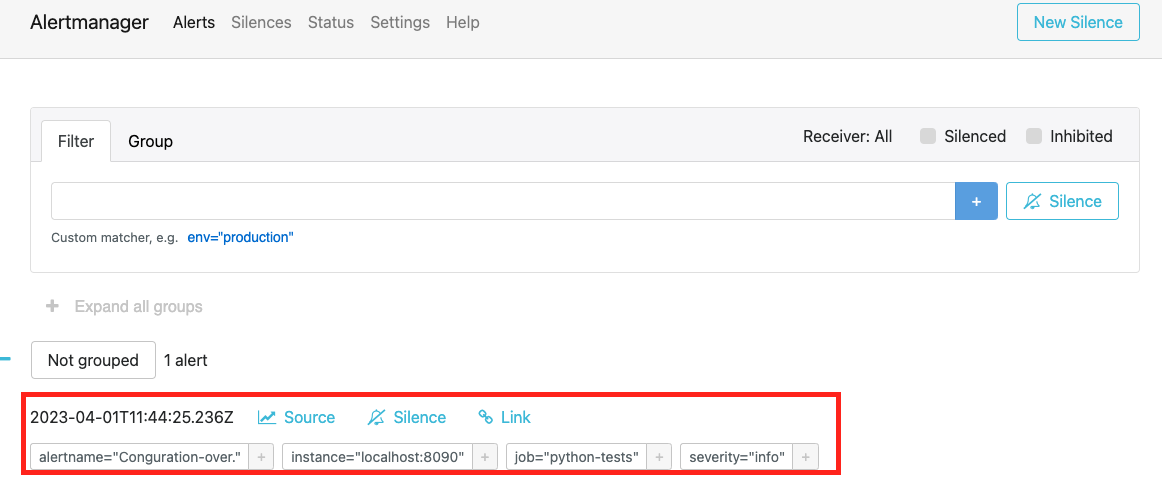
그리고 약 15초(alertmanager 설정) 기다리면 slack채널에 알림이 보입니다.
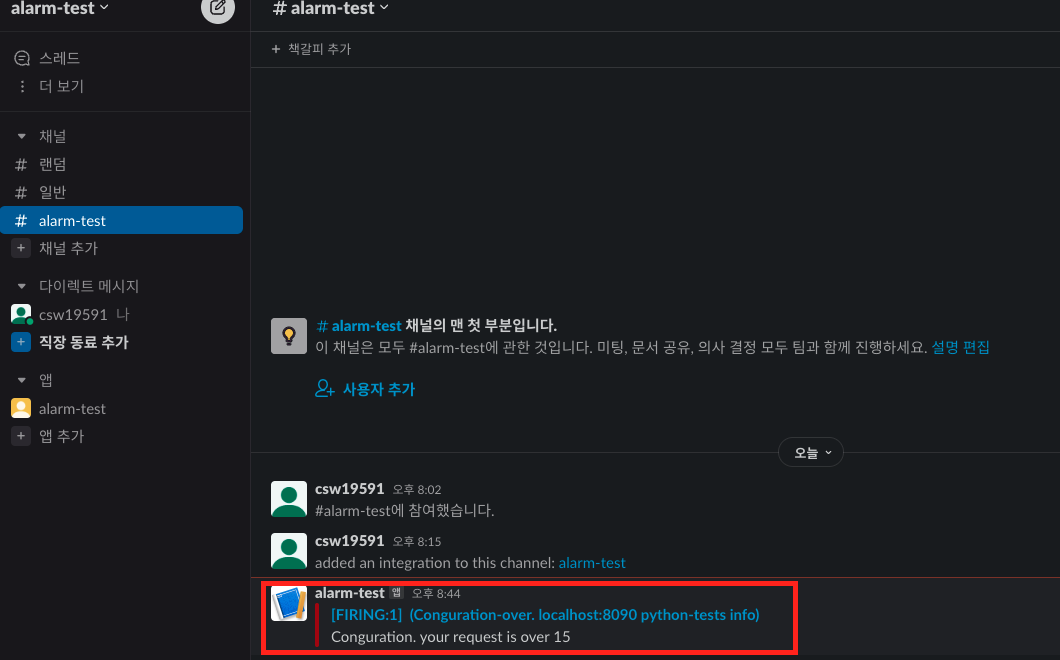
6.4 프로메테우스 오퍼레이터 알림 예제
프로메테우스 알림설정을 챕터[6.2] ~ [6.3]에서 실습해봤습니다. 단순히 slack에 알림을 전송하고 싶은데 여러 군데 수정하고 프로메테우스를 재부팅해야 했습니다. 프로메테우스 오퍼레이터를 사용하면 간단하게 알림설정을 하고 재부팅이 필요없습니다.
- 알림 설정
[챕터 6.2]에서 만든 알림 설정은 prometheusrule CRD로 간단히 설정할 수 있습니다. 주의할 점은 namespace와 labels입니다. 두 값을 잘못 설정하면 프로메테우스 알림이 등록 안됩니다.
# alert_rule.yaml
kind: PrometheusRule
apiVersion: monitoring.coreos.com/v1
metadata:
name: hello-world-request
# namespace는 prometheus가 설치된 namespace로 설정
# prometheus CRD설정에 따라 같은 namespace에 없어도 된다.
# 지금은 예제이므로 같은 prometheus CRD가 설치된 namespace를 사용
namespace: monitoring
# 라벨이 잘못설정되면 alarm rule이 등록안된다.
labels:
release: kube-prometheus-stack
spec:
groups:
- name: helloworld
rules:
- alert: HelloWorld
expr: hello_world_requests_total > 50
labels:
severity: info
라벨과 namespace설정을 위해 prometheus CRD로 설치된 프로메테우스 설정을 봐야합니다. 이 글에서는 쿠버네티스 스택으로 설치된 기본 prometheus 설정을 따릅니다. 프로메테우스 오퍼레이터 공식문서에 따르면, spec.ruleSelector에 설정된 값을 prometheus CRD labels에도 설정해야 알림으로 인식됩니다. 프로메테우스 스택 설정은 release로 되어 있습니다.
kubectl -n monitoring get prometheus | more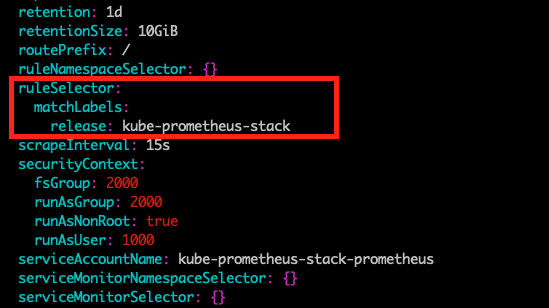
설정한 prometheusrule CRD를 kubectl apply명령어로 생성합니다.
kubectl apply -f alert_rule.yml
prometheusrule CRD를 잘 설정했다면, 약 15초 뒤에 알림이 등록됩니다. 저는 등록한 시점에 이미 알림조건이 충족되어 알림이 Fire되었습니다.
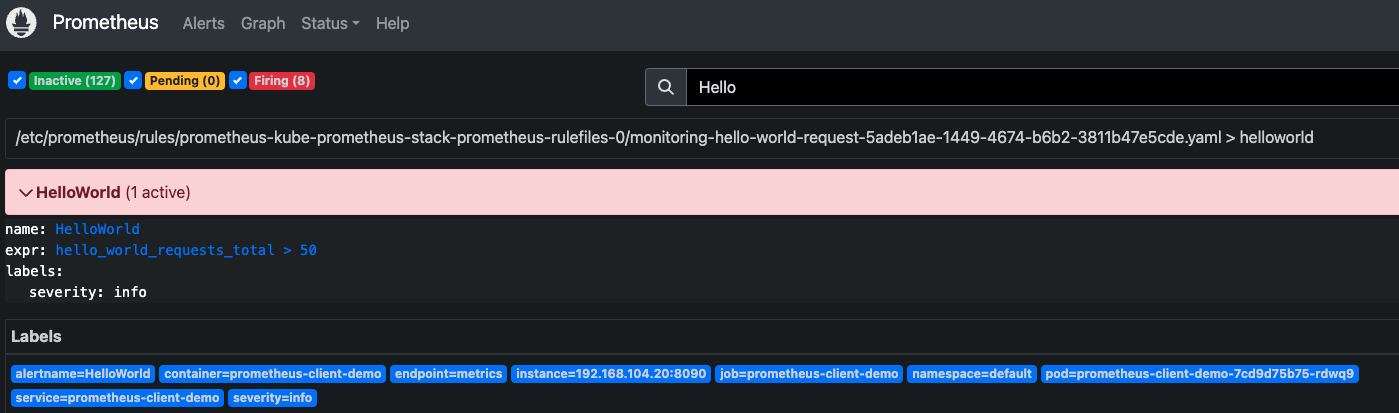
- alertmanager 생성
프로메테우스 오퍼레이터에서는 alertmanager CRD로 생성합니다. 아래는 alertmanager를 생성 예입니다.
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
spec:
replicas: 3
프로메테우스 스택을 설치하면 기본으로 alertmanager 1개가 설치되어 있습니다.
kubectl -n monitoring get alertmanager
이 글에서는 기본으로 설치된 alertmanager를 사용합니다.
- alertmanager에 slack알림 설정(오류 해결못함... 😂😂)
현재, slack으로 잘 전송이되지만 알림인식이 거절되어, 오류메세지가 slack으로 전송되고 있습니다. 아직 프로메테우스 오퍼레이터 설정이 익숙치 않아 설정이 잘못된 것 같습니다. 나중에 업무로 다루게 되어 익숙해진다면... 글을 수정하겠습니다.
alertmanager에서 slack으로 전송하기 위해 slack정보를 설정해야 합니다. 이 설정은 챕터[6.3]에서 alermanager.yml파일로 설정했었는데요. 프로메테우스 오퍼레이터에서는 AlertmanagerConfig CRD로 slack설정을 할 수 있습니다.
먼저 slack 웹훅주소를 secret으로 생성합니다.
apiVersion: v1
kind: Secret
metadata:
name: slack-webhook-url
namespace: monitoring
data:
url: ${base64인코딩된 웹훅주소}
그리고 AlertmanagerConfig CRD를 설정합니다. 주의사항은 labels.alertmanagerConfig에 alertmanager CRD로 생성한 alertmanager이름을 잘 입력해야 합니다.
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: slack-example
namespace: monitoring
labels:
# alertmanager 이름 잘못설정하면 등록안됨
alertmanagerConfig: kube-prometheus-stack-alertmanager
spec:
route:
receiver: 'hello-request'
groupBy: ['test']
groupWait: 15s
groupInterval: 1m
repeatInterval: 1m
receivers:
- name: 'hello-request'
slackConfigs:
- channel: '#alarm-test'
apiURL:
name: slack-webhook-url
key: url
text: 'Conguration. your request is over...'
- 알림 발생
파이썬 웹 애플리케이션 pod를 수동으로 접근하여 API를 호출합니다.
# pod IP 조회
kubectl get po -o wide
# pod IP로 접근하여 API 호출
curl ${pod IP}
프로메테우스 서버에 접속하여 알림이 Fire되었는지 확인합니다.
alertmanager에 접속하여 프로메테우스가 전송한 알림을 받았는지 확인합니다.
현재 AlertmanagerConfig설정을 잘못하여 alertname이 잘못 설정되고 있습니다.
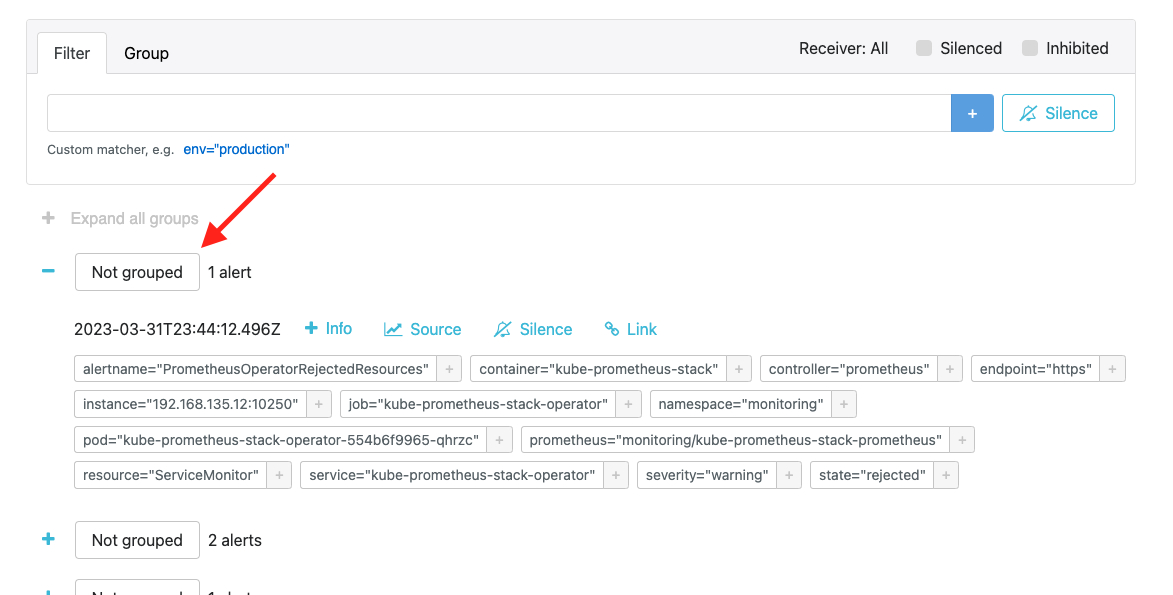
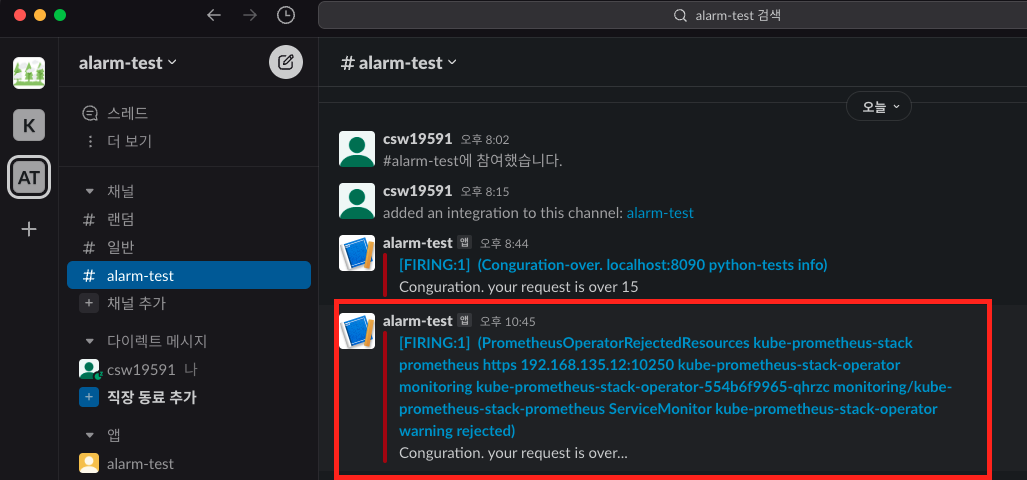
마지막으로 slack 메세지가 왔는지 확인합니다.
현재 AlertmanagerConfig설정을 잘못하여 slack메세지 일부가 잘못전달되고 있습니다.
마치며
alertmanager부분은 처음접하는 부분이어서 많은 시간을 투자했습니다. 그러다보니 글이 정황없이 써진 것 같습니다. 😂 멘탈이 많이 털린건 비밀..
프로메테우스 오퍼레이터에서 타겟설정은 안정화 단계인 것 같아 실무에 적용해도 좋을 것 같습니다. 하지만 alertmanagerconfig CRD가 alpha단계여서 알림설정은 global설정으로 하는편이 좋아보입니다. 시간이 지나 업무에 프로메테우스 오퍼레이터를 사용한다면, 이 글에서 다룬 스터디 내용이 중요한 경험일 것 같습니다.
참고자료
[1] 프로메테우스 알림 설정 공식문서: https://grafana.com/blog/2020/02/25/step-by-step-guide-to-setting-up-prometheus-alertmanager-with-slack-pagerduty-and-gmail/#how-to-set-up-slack-alerts
[2] 프로메테우스 오퍼레이터 공식문서: https://prometheus-operator.dev/docs/prologue/introduction/
[3] 프로메테우스 오퍼레이터 alertmanagerconfig CRD: https://github.com/prometheus-operator/prometheus-operator/blob/main/jsonnet/prometheus-operator/alertmanagerconfigs-crd.json
[4] 프로메테우스 오퍼레이터 예제: https://nangman14.tistory.com/75#5.%20PrometheusRule%20%EC%83%9D%EC%84%B1-1
이하공백
'연재 시리즈' 카테고리의 다른 글
| pkos 스터디 5주차 2편 - pod에서 인스턴스 메타데이터 접근 가능하면 생기는 위험 (0) | 2023.04.03 |
|---|---|
| pkos 스터디 5주차 1편 - AWS EC2 인스턴스 메타데이터 (0) | 2023.04.03 |
| pkos 스터디 3주차 4편 - argo cd와 gitlab파이프라인 연동 (2) | 2023.03.26 |
| pkos 스터디 3주차 3편 - git서비스 gitlab (0) | 2023.03.25 |
| pkos 스터디 3주차 2편 - 도커 레지스트리 harbor (0) | 2023.03.25 |