개요
이 글은 쿠버네티스 환경에서 사내 데이터과학자 만든 AI모델을, 사내에서 같이 사용할 수 있는 방법을 설명합니
다.
데모 영상(19초)에서 보는 것 처럼, chatGPT와 거의 비슷한 웹 페이지에 사내에서 개발한 AI모델을 공유함으로써, 회사원들이 쉽게 사내 AI를 사용하는게 목표입니다.

이전 글에서 설명한 것처럼 LM studio 등을 사용하면 AI 모델을 로컬에서 사용할 수 있습니다. 하지만 회사는 혼자서 일하는게 아니고 다른 사람과 협업을 하기 때문에, LM studio같이 AI 모델을 같이 사용할 수 있는 환경이 필요합니다.
- LM studio 설명: https://malwareanalysis.tistory.com/794
아키텍처
아키텍처는 크게 2개입니다. 프론트엔드 역할을 하는 open WEBUI와 AI모델을 관리하고 실행하는 Inference server가 있습니다.

open WEBUI는 chatGPT와 같이 채팅화면과 프로젝트 등의 기능을 제공합니다. 그리고 프로덕션에 사용할 만큼 운영기능을 제공합니다. SSO, RBAC을 지원하고 인증과 인가를 할 수 있습니다. 또한, observability기능이 있어 prometheus 등으로 모니터링 할 수 있습니다.
프론트엔드에서 사용자 요청을 AI로 실행하려면 Inference server가 필요합니다. Inference server는 모델을 실행할 수 있도록 API를 노출시키고 사용자 요청이 오면 AI를 실행하고 결과를 리턴합니다. 그리고 AI가 실행될때 최적의 환경에서 실행되게 하는 관리 알고리즘을 가지고 있습니다. Inference server는 현재 춘추전국시대여서 계속 출시되고 있습니다. 25년 8월 기준 vLLM이 많이 사용되는 것 같습니다.
아쉽게도 ARM계열 MacOS에서는 vLLM을 사용할 수 없습니다. 25년 8월 기준으로 vLLM은 아직 ARM을 지원하지 않기 때문입니다. 따라서 저는 Ollama를 사용했습니다. 데모용으로는 Ollama가 적합하지만 운영환경에서는 vLLM을 사용하는 것을 추천합니다.
설치 방법
설치에 사용한 예제코드는 저의 github에 공개되어 있습니다.
- github 링크: https://github.com/choisungwook/portfolio/tree/master/mlops/mcp_and_openwebui
쿠버네티스 설치
저는 kind 클러스터로 쿠버네티스를 설치했습니다.
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: openwebui
nodes:
- role: control-plane
image: kindest/node:v1.32.5
extraPortMappings:
# ollama nodePort
- containerPort: 30080
hostPort: 30080
protocol: TCP
# openwebui nodePort
- containerPort: 30090
hostPort: 30090
protocol: TCP
- role: worker
image: kindest/node:v1.32.5
- role: worker
image: kindest/node:v1.32.5Inference server(Ollama) 설치
Inference server역할을 하는 Ollama는 helm chart를 사용했습니다.
helm 저장소를 추가합니다.
helm repo add otwld https://helm.otwld.com/
helm values는 아래처럼 설정했습니다. 핵심 설정은 ollama.models입니다. ollama pod가 실행되면 ollama가 관리하는 모델을 ollama 저장소(https://ollama.com/library)에서 다운로드 받습니다. models.pull을 사용하면 AI모델을 그대로 다운로드 받고 models.create를 사용하면 AI모델 다운로드 받고 파라미터를 설정합니다.
# ref: https://github.com/otwld/ollama-helm/blob/main/values.yaml
ollama:
gpu:
enabled: false
# ref: https://ollama.com/library
models:
pull:
- llama3.1:8b
# AI 모델 파라미터 수정
create:
- name: llama3.1-ctx16384
template: |
FROM llama3.1:8b
PARAMETER num_ctx 16384
위 설정한 helm values를 사용하여 ollama를 설치합니다. helm values를 보면 아시겠지만, 이 예제에서는 AI 모델 2개를 다운로드 받습니다. 2개 모델의 크기 합이 10GB가 넘고 다운로드가 약 5분이상 걸립니다. 즉, pod 생성시간이 5분 이상 걸립니다.
# ollama 배포
helm upgrade --install ollama otwld/ollama \
--namespace ollama --create-namespace \
-f ./charts/ollama/values.yaml
# pod 확인
kubectl get pod -n ollama
ollama pod는 내부적으로 아래 명령어를 사용해서 AI모델을 다운로드 받습니다.

ollama pod가 정상적으로 실행되면 ollama API를 호출해보세요. Ollama is running이라는 문자열을 볼 수 있습니다. port-foward로 ollama API를 노출 시킬 수 있습니다.
kubectl -n ollama port-forward svc/ollama 11434:11434

open webui 설치
open webui는 helm chart를 사용해서 설치했습니다.
open webui helm 저장소를 추가합니다.
helm repo add open-webui https://helm.openwebui.com/
helm values는 아래처럼 설정합니다. 사용하지 않는 기능은 false처리했습니다. 그리고 open webui에 ollama API를 호출할 수 있도록 ollama 쿠버네티스 서비스 디스커버리 주소를 사용했습니다. 또한 저는 ingress대신 nodePort를 사용하여 open webui에 접근하도록 했습니다. kind 클러스터에서 ingress를 사용하려면 hosts파일을 설정해야되서 nodePort를 사용했습니다. 운영환경에서는 ingress를 사용하는 것을 권장합니다.
ollama:
enabled: false
websocket:
enabled: false
pipelines:
enabled: false
persistence:
enabled: false
service:
type: NodePort
port: 80
containerPort: 8080
nodePort: 30090
# kubernetes service discovery endpoint: kubectl -n ollama get svc ollama
ollamaUrls:
- "http://ollama.ollama.svc.cluster.local:11434"
helm values의 ollamaUrls는 open webui에서 아래처럼 설정됩니다. Admin panel의 Connections페이지에 설정됩니다.

위 설정한 helm values를 사용하여 open webui를 설치합니다.
helm upgrade --install open-webui open-webui/open-webui \
--namespace open-webui --create-namespace \
-f ./charts/open-webui/values.yaml
open webui는 port-forward로 접속하거나 저처럼 nodePort 또는 ingress로 접속하시면 됩니다.
kubectl -n open-webui port-forward svc/open-webui 8080:80
open webui에 접속하면 chatGPT와 비슷한 화면이 나오고 ollama에 있는 모델을 불러올 수 있습니다.

채팅창에 Hello world라고 입력하면 open webui가 ollama에게 API를 사용해서 사용자 요청을 전달합니다. 그리고 ollama는 AI모델을 실행하고 실행한 결과를 open webui에 리턴합니다. open webui는 리턴값을 받아 화면에 출력합니다.

hello world를 open webui에 요청했을 뿐인데 순간 CPU 사용률이 1400%까지 올라갔습니다.

더 공부할 것
AI모델을 어떻게 Inference server에 배포해야할지?
이 글의 예제는 Inference server에 AI모델이 있다고 가정했습니다. 실제 환경에서는 AI모델을 Inference Server에 배포하는 파이프라인이 필요합니다.

멀티테넌트가 필요할지?
open webui는 SSO, RBAC을 지원하지만, 다른 팀 또는 다른 사람의 작업으로 open webui가 장애가 났을 때 다른 사람에게 영향이 안가도록 하려면 멀티테넌트가 필요합니다. 그렇다면 실제 환경에서는 어떻게 멀티테넌트를 구현할지 고민해야합니다.

Inference server 관리와 AI gateway연동 또는 router 연동
이 글의 예제에서는 간단히 Inference server를 ollama를 사용하고 단일 모델을 사용했지만, 실제 운영환경은 여러 모델을 사용하고 여러 모델이 잘 요청을 받아 실행할 수 있도록 해야합니다. 입문자는 운영 노하우가 없기 때문에 가능한 프레임워크 아키텍처를 공부하고 프레팀워크를 사용하던지 참조하여 좋은 아키텍처를 만들어야 합니다. 아래 예제는 vLLM 아키텍처입니다. 여러 모델을 실행할 수 있도록 vLLM 엔진을 n개 실행하고, 사용자 요청을 vLLM 엔진에 라우팅 할 수 있도록 라우터라는 컴퍼넌트가 있습니다.
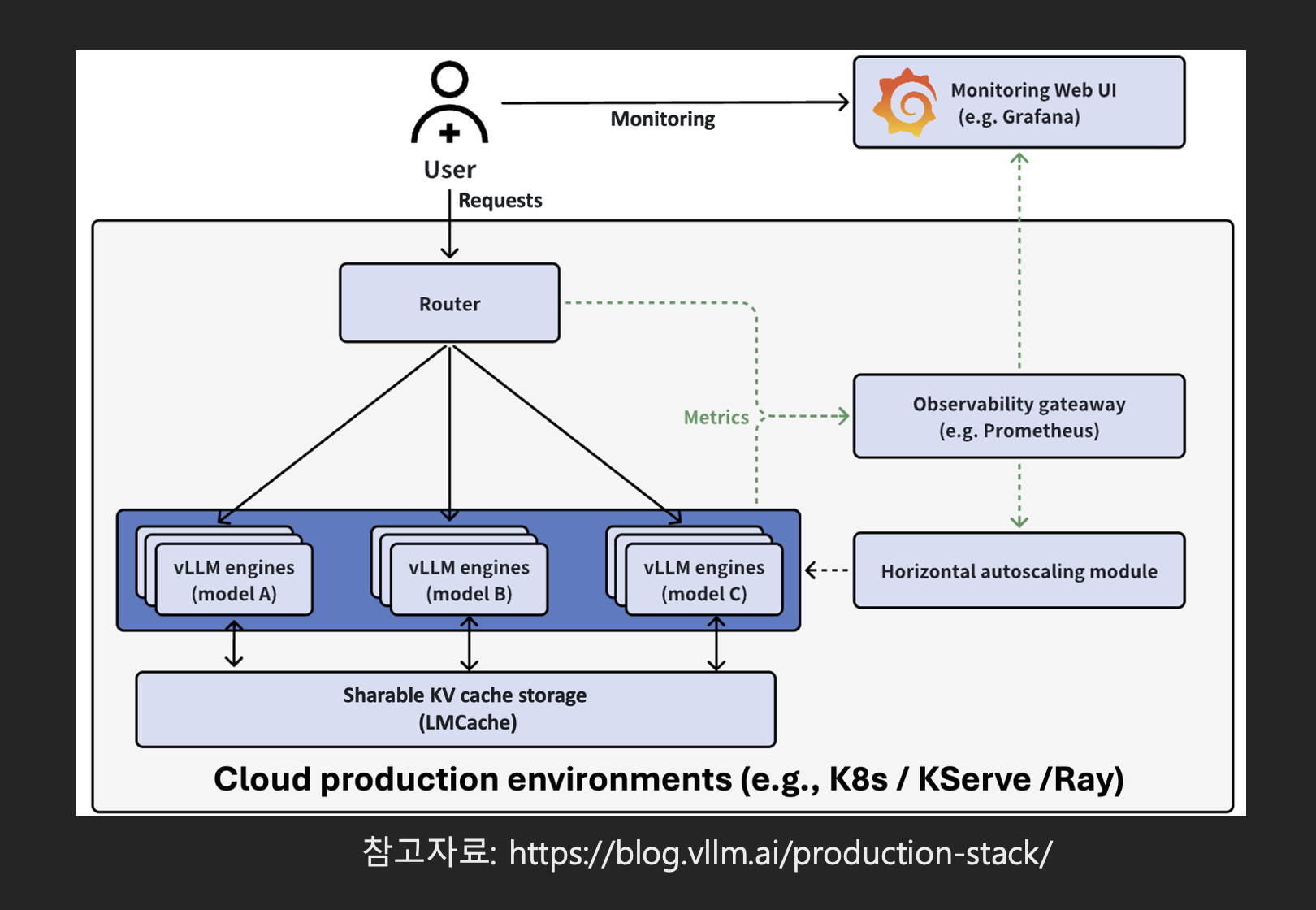
Observability
소프트웨어서도 Observability가 중요한 만큼 AI에서도 Observability가 중요합니다. AI가 어떻 생각과정을 거쳐서 어떤 결과를 냈는지 트레이싱과 로그, 메트릭을 남겨야 합니다. 또한 비용을 얼마나 사용했는지 모델 사용을 제한할 수 있는지 등의 대한 메커니즘이 필요합니다. LiteLLM, langfuse가 Observability와 AI접근을 제한할 수 있습니다.
리스스관리
AI를 한다면 GPU가 많이 언급되는데, 실제로는 CPU, Memory, Storage, Network 모두 잘 관리해야 합니다. 모델 파라미터와 처리할 수 있는 컨텍스트를 고려하여 Memory를 계산해야하고, 수많은 AI모델을 저장하고 빠르게 접근할 수 있는 스토리지, AI모델이 필요한 네트워크 특히 GPU 타임슬라이스 등을 사용하면 네트워크 트래픽이 엄청나게 늘어납니다. 따라서 GPU뿐만 아니라 다른 리소스도 관리해야 합니다.

참고자료
- open-webui helm charts: https://github.com/open-webui/helm-charts
- openAI API spec: https://platform.openai.com/docs/api-reference/introduction
- vLLM not support multiple models: https://docs.vllm.ai/en/v0.5.1/serving/faq.html
- Starting with OpenAI-Compatible Servers:https://docs.openwebui.com/getting-started/quick-start/starting-with-openai-compatible
- ollma parameter in helm charts: https://oleg.smetan.in/posts/2025-02-14-ollama-helm-chart-llm-context
'전공영역 공부 기록' 카테고리의 다른 글
| kubeflow에서 illegal instruction (core dump)에러 해결방법 (3) | 2025.08.17 |
|---|---|
| vscode notebook(ipynb)파일을 파이썬 코드로 변환하는 방법 (0) | 2025.08.16 |
| ISMS-P 인증 심사 인터뷰 후기 (0) | 2025.07.22 |
| Github Copilot으로 Pull Request에서 쿠버네티스 설정 리뷰 받는 방법 (1) | 2025.07.13 |
| Datadog cloudwatch 메트릭기반 알람의 주의사항 (2) | 2025.07.06 |